


#1-1 딥러닝 기본 용어 설명
■ 딥러너가 되려면?
- 구현 기술
- 수학 기술 (Linear Algebra, Probability)
- Knowing a lot of recent Papers
- 어떤 트렌드, 논문, 연구들이 발표되는지 아는 것
■ AI
- AI[ML{DL()}]
- AI: Mimick human intelligence (인간의 지능을 모방)
- ML: Data-driven approach (데이터 기반의 학습)
- DL: Neural Networks (NN 모델을 사용)
■ 딥러닝 주요 키워드 (※ 이 4가지 항목에 비추어 연구, 논문을 보면 이해↑)
- data: the model can learn from
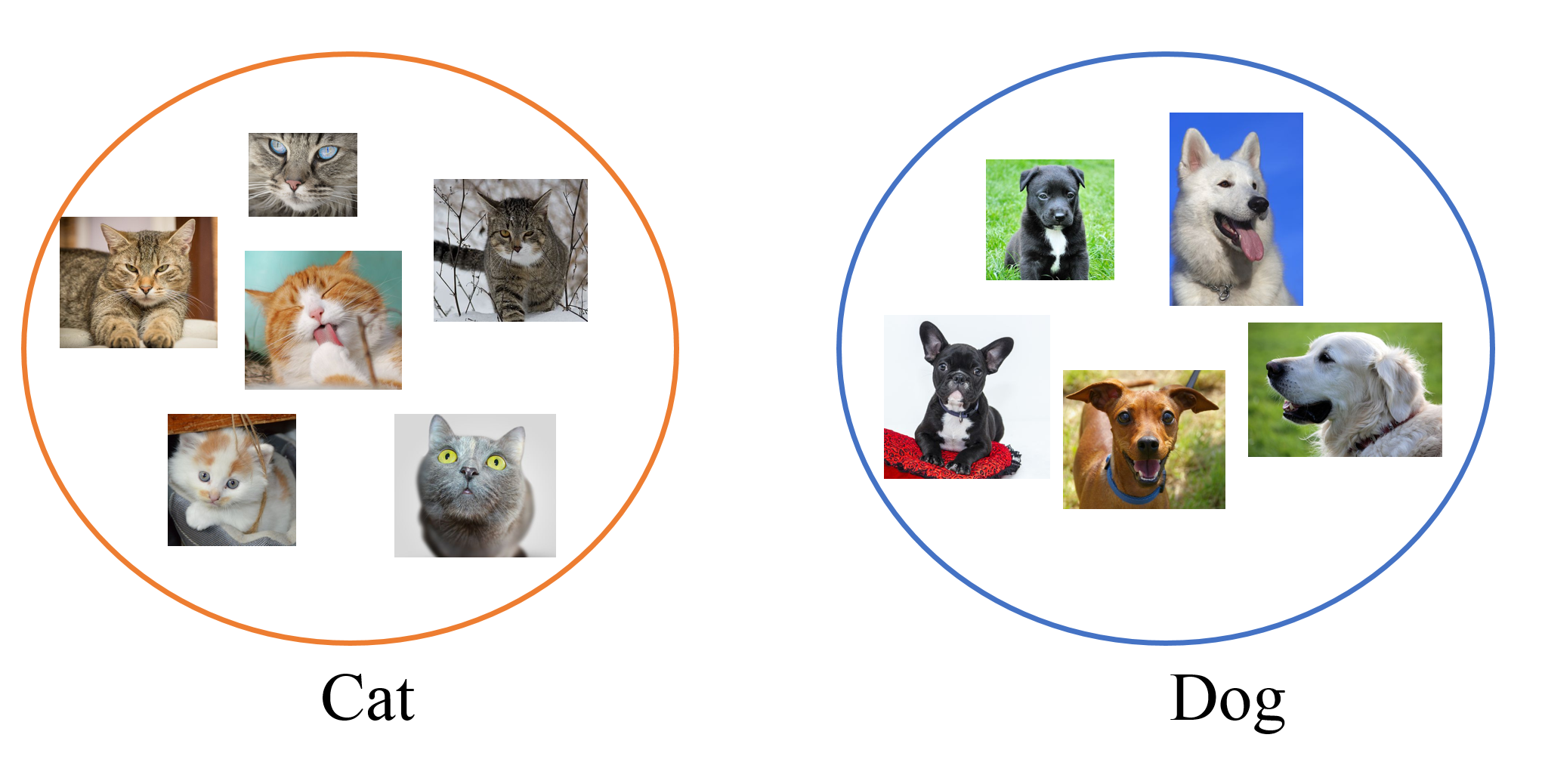
- Classification: 강아지, 고양이 분류
- Semantice Segmentation: 이미지의 픽셀별로 어떤 클래스에 속하는지
- Detection: 이미지 내 물체의 바운딩 박스를 찾음
- Pose Estimation: 사람의 2,3차원 스켈레톤 정보
- Visual QnA: 이미지와 질문이 주어졌을 때, 질문의 답 구함




- model: how to transfrom the data (이미지를 라벨로 학습)
- AlexNet, GoogLeNet, ResNet, DenseNet
- LSTM, Deep AutoEncoders, Gan
- loss: quantifies the badness of the model (목표 근사치)
- Regression Task: MSE (Mean Squared Error)
- Classification Task: CE (Cross Entropy)
- Probabilistic Task: MLE (Maximum Likelihood Estimation)
- algorithm: adjust the parameters to minimize the loss
#1-2 Historical Review
■ Historical Review
- 2012 AlexNet
- 만년 유망주 딥러닝이 실제적으로 성능을 발휘
- 모든 기계학습의 판도가 바뀜
- 2013 DQN
- 알파고의 알고리즘(딥마인드)의 시초
- 2014 Encoder/Decoder, Adam
- Encoder/Decoder:
- # 단어의 연속이 주어질 때 해석하여 또 다른 단어의 연속으로 만듦
- Adam: (웬만하면 잘 된다)
- 2015 GAN, ResNet
- GAN: Generative Adversarial Network
- ResNet: Residual Networks
- # 딥러닝을 딥러닝답게 발돋움 (네트워크가 깊게 쌓을 수 있게 됨)
- 2016
- 2017 ✨Transformer (논문제목: Attentoin is all you need)
- 2018 Bert
- Bidirectional Encoder Representations from Tranformers
- find-tuned NLP models
- # 말뭉치를 피처링해서 풀고자 하는 소수의 데이터에 fine-tuning
- 2019 Big Language Model(GPT-X)
- fine-tuning의 끝판왕, 굉장히 많은 파라미터로 이뤄진 모델
- 2020 Self-Supervised Learning
- SimCLR
- 한정된 학습 데이터를 외에 라벨을 모르는 unsupervised 데이터 활용
- Self-Supervised data Sampling
- # 데이터 이해도가 뛰어날 때 학습 데이터 자체 생성
#1-3 뉴럴 네트워크-MLP
■ NN
- function approximator
- Linear NN (1차원)
- Data: 1차원 상의 x, y의 n개가 모여있는 데이터
- Model: x에서 y_hat으로 가는 mapping 찾는 것
- Loss: 이루고자 하는 현상이 이뤄졌을 때 줄어드는 함수
- w 업데이트 방법 in MSE
- 1) loss func. 을 w로 편미분 한 값을 찾아서
- 2) 현재 w의 편미분 값의 적절한 값을 곱해서 빼 줌
- bias 업데이트 방법 in MSE
- 1) w에 대해서 편미분을 구함
- 2) b에서 대해서 편미분을 구함
- 3) 각각 w와 b에 대해서 특정 step size만큼 편미분값을 곱해서 빼줌
- 행렬곱: 두 개의 백터 스페이스 간의 변환
■ Multi-Layer-Perceptron
- 네트워크를 여러 개 쌓는 법
- 그저 다시 곱하면 그냥 행렬곱에 지나지 않음 (Deep learning이 아님)
- # 한 단짜리 NN이라 볼 수 있음
- 중간에 Nonlinear transform 필요
- # 네트워크가 표현할 수 있는 표현력 극대화
- # Activation functions이 그 예
■ DNN
- Hierarchical Representation Learning (계층적 표현 학습)
#2-1 Optimization
■ Gradient Descent
- 1차적으로 미분한 값에 계속 최적화하여 local minimum 찾아감
■ Optimization
- Generalization: 일반화 성능 향상
- (training error = 0)이 항상 최적값이 아님
- 어느 순간 test error 발생하고 Generalization gap 발생
- Generalization이 좋다고 해서 test 성능이 좋다고 할 순 없음(gap만 적은 것이니까)
- Overfitting, underfitting이 그 예
- Underfitting vs. Overfitting
- Overfitting: train data ↑ / test data ↓
- Underfitting: train data ↓ / test data ↓
- Cross-validation (or K-fold validation)
- train dataset에서 또 다시 train data와 test data를 나눠서 중간 평가
- cv로 최적의 파라미터 set을 찾고 파라미터 고정 후 모든 데이터 사용
- Bias & Variance
- Variance: 입력 시 출력이 얼마나 일관되는지
- # high variance: overfitting 가능성 있음
- Bias: 평균적으로 봤을 때 출력이 타깃과 얼마나 가까운지
- Bias & Variance Tradeoff
- # cost를 minimizing 하는 것은 세 영역 중 하나가 최소화 되는 것
- # cost ≒ (bias²) + (variance) + (noise)
- # 하나가 최소화 되면 또 다른 것들은 증가할 확률 큼
- Bootstrapping
- 학습 데이터 일부 샘플링 하여 여러 모델 생성
- Bagging vs. Boosting
- Bagging (Bootstrapping aggregationing) : Bootstrap + 앙상블
- Boosting : weak laerner들을 sequential 하게 합침
#2-2 GD Methods
■ Gradient Descent Methods
- Stochastic Gradient Descent
- 하나의 샘플로만 gradient 해서 업데이트
- Mini-batch Gradient Descent
- 부분 데이터(batch) 샘플링 gradient 업데이트, 반복
- Batch Gradient Descent
- 한 번에 다 사용하고 모두의 gradient 평균으로 업데이트
■ Batch-size Matters
- 관련 논문
- 큰 배치를 활용하면 sharp minimizers에 도달
- 작은 배치를 활용하면 flat minimizers에서 도달 (이게 더 좋다~)
- # generalization gap이 더 적음
■ Gradient Descent Methods+
- (Stochastic) Gradient Descent
- Gradient Descent: lr에 너무 의존
- Momentum
- 이전 batch의 방향 정보 이어감
- # gradient가 왔다 갔다 해도 어느 정도 학습 유지
- momentum과 현재 gradient를 합친 accumulation gradient로 업데이트
- Nesterov Accelarated Gradient (NAG)
- accumulation gd를 계산할 때 Lookahead gredient가 쓰임
- # 파라미터의 다음 위치의 근사치로 기울기를 계산
- # 일단 관성 방향 먼저 움직이고 움직인 자리에서 gradient 계산
- momentum은 관성 때문에 local minimum으로 convergen(수렴) 하지 못함
- Adagrad
- 각 파라미터가 얼마큼 변했는지 값을 저장 = G (Sum of gradient squares)
- # 계속 G가 커지기에 결국 무한대로 감.
- # 분모가 커지니까 뒤로 갈수록 학습이 멈춰짐
- adapted learning
- Adadelta
- lr이 없음 (바꿀 수 있는 요소가 많이 없기에 많이 사용 X)
- 1) 비효율적으로 이전의 제곱된 기울기를 저장하여 평균을 계산하지 않고,
- 2) 이전에 제곱된 기울기의 이동 평균을 이용하여 평균을 계산
- RMSprop
- 논문 X, 제프리 힌튼이 강의에서 한 말
- 그냥 stepsize 추가 (이전 맥락 상황 봐가며 하도록)
- Adam (Adaptive Moment Estimation)
- RMSProp + Momentum
#2-3 Regularization


■ Regularization
- generalization gap을 줄이고 train set뿐만 아니라 test set에도 잘 동작하도록 취함
- Early Stopping
- Validation error를 활용하여 loss가 어느 시점 이상 커질 때 멈춤
- Parameter Norm Penalty
- NN 네트워크 파라미터가 너무 커지지 않도록 함
- 학습할 때 네트워크의 weight들의 숫자들이 작을수록 좋음
- # function space에서 함수를 부드럽게 함 (=generalization gap이 적을 것으로 예상)
- Data Augmentation
- 주어진 데이터를 변환하여 데이터양 늘림 (label이 바뀌지 않는 한도 내에서)
- Noise Robustness
- Add random noises inputs or weights
- Lebel Smoothing
- 라벨을 섞음
- 분류 성능 향상: Mixup(겹침), Cutout(자름), CutMix(사진합성)
- Dropout
- 일부 weight을 0으로 만듦
- Batch Normalization
- B.N을 적용하려는 layer에 statistcs를 정규화
- Group Normalization 논문
- # Batch Norm, Layer Norm, Instance Norm, Group Norm
'AI 배우기 > 딥러닝' 카테고리의 다른 글
| [부스트코스] 딥러닝 기초 다지기 3~5 (0) | 2023.09.17 |
|---|