


자료 출처: https://youtu.be/TwF2EB9UCsI?si=TSwClVyazRngfV_h
■ 발표자 소개
- 김윤수, 서울대 경제 / 인공지능 전공 학부생
- 캐글 그랜드마스터
- 캐글 최고 랭킹 22위
- 개인 공부법
- 인터넷을 통해서 최신 정보들을 얻는 것이 효과적
- 온라인 강의로 이론을 빠르게 접하고 대부분의 시간 캐글 투자
- 기초 이후 프로젝트, 대회 진행하며 필요할 때 양질의 자료 구하는 것이 효과적이었음
- Upstage Global Residency
- 업스테이지 인턴 같은 포지션
- 주로 캐글 대회 참여하여 좋은 성적 내는 데 집중
- # 팀 또는 개인으로 1~2달간 대회 진행
- # 좋은 성과를 얻은 경우 업스테이지 톡 등을 통해 솔루션 공유
- 그랜드마스터가 되기까지 원동력 1 [기초]
- 영어 : 최신 기술, 논문 구글링 할 때 자연스러운 이해를 위해 필요
- 구글링 : 코딩이나 최신 정보에 대해 궁금하거나 필요할 때 필요
- 코세라 : 퀄리티 좋고 잘 정리됨, 영어 주의
- 그랜드마스터가 되기까지 원동력 2 [캐글]
- 열정: 무엇인가 새롭게 만들고 순위를 올리는 재미
- 시간: 약 2달을 잡고 전 세계 사람들과 경쟁
- 장비: 데이터가 큰 대회는 장비가 없으면 리더보드 상위권이 힘듦
- 그래픽 메모리가 부족한 경우도 있음
- 당장 구하기 힘들다면 Colab Pro TPU 활용도 좋음
- 훌륭한 팀원: 함께하면 동기부여, 많은 시도가 이뤄짐
■ 캐글 소개
- Why 캐글 [AI 개발자로서의 성장]
- 대회에서 랭킹을 높이기 위해
- 자연스레 최신 기술들을 찾아보게 됨
- 여러 시행착오를 통해 경험 축적, 접근방법들에 대한 이해도 증가
- 직접 코드를 짜고 대회기간 동안 계속 업데이트/디버깅해야 하므로 코딩 실력 상승
- 다양한 분야(cv, nlp, tabular)의 대회 참여하면 각 분야별 SOTA 기술 습득
- 캐글의 공유 문화: 캐글러들의 코드, 아이디어 공유가 초보자에게 많은 참고가 됨
- 랭킹 시스템으로 본인의 실력을 외부에 객관적으로 보여줄 수 있음
- 무엇보다 재미있다!
- Kaggle Code (a.k.a. 주피터 노트북)
- 컴피티션 참가 시 베이스라인 코드나 EDA 참고 가능
- 코랩과 다른 점
- 커뮤니티 형식: 보팅 & 댓글
- 캐글 서버 내 수많은 데이터셋 연동 가능
- Copy & Edit 기능: 다른 사람 코드 쉽게 재현 가능
- 버전 관리
- Kaggle Discussion: 아이디어 창고
- 대회 전반에 대한 포럼
- 모델 성능 개선을 위한 아이디어들이 숨어있음
- 다른 사람의 경험을 참고하여 시행착오를 줄이자
- Kaggle Datasets: 데이터 공유의 장
- 수십 GB 용량의 데이터를 누구나 업로드/다운로드 가능
- 다운로드하지 않아도 캐글 노트북에 로드하여 바로 사용 가능
■ 캐글 대회에서 좋은 성적을 얻기 위한 꿀팁
- 대회 선정
- Shakeup: Public LB의 결과와 Private LB의 결과가 매우 다를 때를 지칭
- 학습시킨 모델이 Private 테스트셋에까지 일반화가 잘 되어 있는지 확인
- CrossValidation Score vs Public LB Score 상관관계 주목
- CV-PublicLB 상관관계 높을수록 PublicLB-PrivateLB 상관관계도 높음
- dicussion에 cv라고 검색하면 cv-lb 상관관계 분석한 글 많음
- 물론 데이터 스플릿과 속성을 살펴보는 것도 중요

- 검증 방법 (LB 시뮬레이션!)
- 검증이 적절하지 못하면?
- 실험 효과 왜곡되어 측정, 모델 개선 지속 어려움
- 주최자가 train/test를 나눈 방법대로 train 데이터셋 쪼갬
- 데이터 전처리 단계에서 fold를 나눠서 파일로 저장한 뒤, 이 고정된 fold 계속 사용
- 실험 전후 비교를 위해서
- sklearn의 KFold, GroupKFold, StratifiedKFold 활용
- OOF(Out Of Fold), 5 fold: 꼭 알아야 하는 학습 체계
- train데이터셋을 fold 수만큼 나누고 단계별로(=split) 각 fold를 번갈아가며 검증
- OOF 장점:
- 1) 더 많은 데이터로 검증 가능: fold 수만큼 prediction 나옴
- 2) 스태킹에 활용: 2차적인 모델의 input 활용 가능
- 3) 다섯 개 모델 앙상블: split별로 각 모델이 학습되는데 fold 수만큼 앙상블 가능
- 예외적인 경우
- 1) 데이터가 너무 많아서 매번 5 fold 학습이 어려울 때
- 하나의 fold만으로 검증
- 하나의 split만 검증하고 최종 모델 제출 시 앙상블
- 2) 과거를 토대로 미래를 예측하는 경우
- 마지막 split만 유의미할 것
- 1) 데이터가 너무 많아서 매번 5 fold 학습이 어려울 때

- 베이스라인 작성 (재사용 가능한 뼈대 코드를 만들자)
- 여러 아이디어들을 추가하는 것이 쉬움 (베이스 생성 시 완벽히 이해하고 있기 때문)
- 코드의 사용을 거듭하면서 코드를 지속적으로 업그레이드 가능
- 새 대회에 참가할 때, 이전 대회 코드를 살짝 수정해서 베이스라인 작성
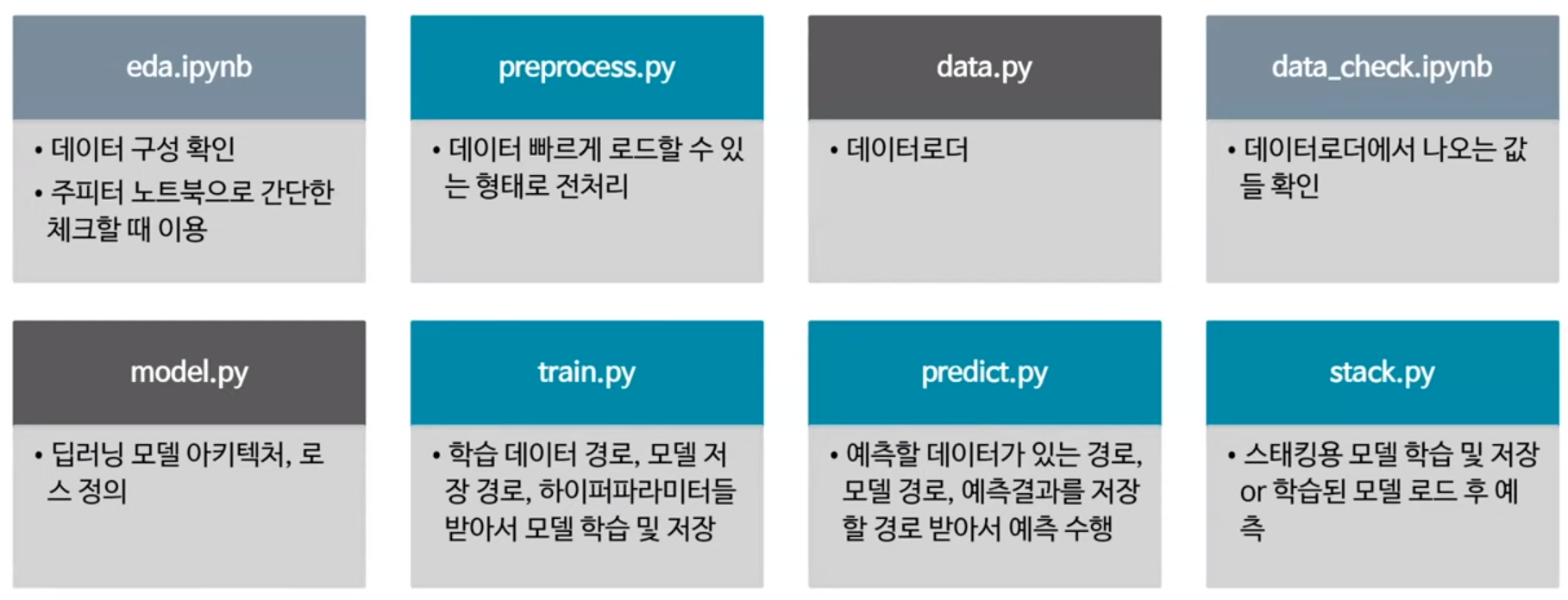
- 점수 올리기
- 가장 중요한 것! 베이스라인을 적절한 모델로 버그 없이 작성 (이것만 해도 메달권)
- 하나의 아이디어를 실행할 때 여러 세팅으로 실험하는 게 중요
- 사소한 디테일 차이로 갈리기도 함
- 앙상블: 점수를 올리는 보증수표
- 거의 모든 경우에서 모델의 성능/안정성을 향상
- 거의 모든 대회 상위권 솔루션에서 사용
- 특히 단일 모델 public 점수가 불안정해도 비교적 안정적인 private 점수 얻는데 도움
- 예측값 다양성이 클수록 앙상블 효과가 큼
- 결합 방법: 평균/가중평균, 스태킹(예시값 결합), n-fold 앙상블, n-seed(랜덤 시드값) 앙상블, 다양한 모델 앙상블
- 많이 사용되는 라이브러리들
- 딥러닝: PyTorch, PyTorch Lightning
- 기본: Jupyter, pandas, numpy, [matplotlib, seaborn](시각화 도구), scikit-learn(ML 관련 튜토리얼 기능 제공)
- GBM (tabular관련 / 딥러닝에 밀렸지만 앙상블 용도로 사용): LightGBM, XGBoost, CatBoost
- Vision:
- 깃허브 저장소 pytorch-image-models(pre-train 된 최신 기술 중요)
- Albumentations(image argumentation), OpenCV(간단한 read, 처리)
- Segmentation Models(pre-train 인코더를 깃헙 tim 저장소와 연동하여 대응)
- NLP: Transformers
- W&B (훈련 트래킹, 로깅)
- OPTUNA(하이퍼파라미터 튜닝, Bayesian 최적화, random search, 고수님은 GBM 학습 시 많이 사용)
■ 대회 금메달 솔루션
- 중요한 순서
- 1) 스킬셋(캐글에서 자주 사용되는 보증된 테크닉들)
- 2) 포럼 (캐글러들의 아이디어 공유)
- 3) 이전 대회 솔루션(비슷한 대회의 상위권 솔루션 참고)
- 4) 데이터 특성(분석 후 본인만의 아이디어 적용)
- 5) 엔지니어링(train/test 환경 동일, 버그 없는 코드)
- 6) 논문 (이론 습득)
- 7) 장비 (큰 사이즈의 모델들은 힘들 수도 있음)
- 고수가 참여한 대회 사례를 통한 TIP
- 적은 데이터, 불안정한 cv-lb점수
- label smoothing: 모델 예측값을 보수적으로 만들어줌
- pseudo labeling: test 셋을 증강하여 재학습
- 앙상블: 리더보드 불안정에서 앙상블은 효과적
- 방대한 시퀀스 형식의 데이터, 타임시리즈 API를 활용한 제출
- 딥러닝 모델 구조: transformer + LSTM
- 데이터가 거치는 모든 변환들을 train/test에서 동일하게 유지
- 앙상블
- 고해상도, 외부 데이터셋, 마스크 정보(segmentation label 활용 가능)
- 마스크 활용 위해 pre-train 도입
- 외부 데이터셋 pseudo labeling
- 고해상도, 큰 모델
- 앙상블
- 텍스트/이미지 데이터 동시 제공, 유사한 아이템 찾아내는 retrieval 문제
- concat & union 방법으로 텍스트/이미지 임베딩 결합
- 임베딩을 더 잘 클러스터링 하기 위한 후처리
- 딥러닝 모델 구조, loss
- 앙상블
- 적은 데이터, 불안정한 cv-lb 점수
- 안정적인 학습 위한 튜닝
- 피쳐 엔지니어링 및 활용 방법
- 스태킹 앙상블