


0. 발표자료: Link
#2 ML Regression Competition | 아파트 실거래가 예측 | 6조.pptx
House Price Prediction 아파트 실거래가 예측 www.fastcampus.co.kr Copyright ⓒ FAST CAMPUS Corp. All Rights Reserved. 무단전재 및 재배포 금지 무적 6조 김윤겸, 남영진, 노균호, 박성우, 이재민, 장호준 #UpstageAILab1기
docs.google.com
1. 대회 개요 : Competition Overview
Goal of the Competition
- 서울시 아파트 실거래가 매매 데이터를 기반으로 아파트 가격을 예측하는 대회
- 서울시 아파트의 각 시점에서의 거래금액(단위:만원)을 예측하는 것이 목표
Timeline
- January 15th, 2024 - Start Date
- January 25th, 2024 - Final submission deadline
Dataset
- train.csv
- 1,118,822개의 행
- 거래금액(target)을 포함한 52개의 아파트의 정보와 거래시점에 대한 변수
- 시점: 2007.01.01 ~ 2023.06.30
- test.csv
- 9272개의 행
- 거래금액(target)을 제외한 51개의 아파트의 정보와 거래시점에 대한 변수
- 시점: 2023.07.01 ~ 2023.09.26
- sample_submission.csv
- 9272개의 행
target예측 결과가 입력될 컬럼
- subway_feature.csv
- 768개의 행
- 지하철역 추가 데이터
- bus_feature.csv
- 12584개의 행
- 버스정류장 추가 데이터

2. 대회 목표 : Competition Detailed Goal
Learning Objective
- 공동 학습 목표
- 1차 목표: 강의 입과 전까지 학습 내용 정리 및 복습
- 강의 입과 후 커리큘럼에 따라 학습 목표 재설정
- 2차 목표: Upstage ML 경진대회가 진행되는 1월 15일 전까지 집값 예측 관련 대회 인사이트 찾기
- 1차 목표: 강의 입과 전까지 학습 내용 정리 및 복습
- 개인 학습 목표
3. 모델 구조 요약 : Competition Model
(flowchart로 대체 예정)
Data Preprocessing
- 재개발 되거나 예측할 필요가 없는 아파트 데이터 삭제
- 결측치 삭제 및 대체
- 결측치는 아니지만 의미 없는 변수 삭제
- 증여 또는 직거래로 인해 나머지 타겟과 다른 양상을 보이는 경우 (이진 분류)
- 도로명 기준 아파트명 결측치 대체
- 아파트명 직접 대체
- 좌표X, 좌표Y 결측치 대체 (Timeover, 실패)
- 결측치 90% 이상 차지하는 변수 제거
- 연속형 변수: 선형보간(Linear interpolation)
- 범주형 변수: ‘NULL’ 임의의 범주로 대체
Feature Engineering
- 시군구, 년월 분할
- 2020년 이후 데이터만 추출
- Trainset에서 Testset에 없는 아파트명을 가진 데이터 제거
- 강남or강북 여부, 신축or구축 여부 변수 생성
- 한국 은행 기준금리 변수 생성
Modeling
- 범주형 변수 Label Encoding
- 6개 모델 Voting 앙상블
- RandomForestRegressor
- XGBRegressor
- LGBMRegressor
- CatBoostRegressor
- HistGradientBoostingRegressor
- 모델별 Out-of-fold 예측값을 생성하고 LADRegression으로 학습시켜서 가중치 생성
- CrossValidation : kfold=5
Result (RMSE)
- Public LB : 46154.9294
- Private LB : 32499.2521
- 개인 Ranking 8/9 (비공식)
- 팀 Rangking 7/9 (공식)
4. 진행 과정 : Competition Process
EDA
부동산에 대해선 까막눈이었던 나는 카더라~말고 실질적으로 도움이 되는 도메인이 필요했고 간단한 조사 후 아래의 의견을 도출해봤다.
- 🚫한강과의 거리 (부산의 경우 바다와의 거리)
- ✅거래일 당시 한은 기준 금리 넣는 건 어떨까
- 🚫주변 스타벅스 여부?
결과적으로 위치와 관련된건 실패했다.
좌표를 생성하는 코드를 대회 중후반부터 돌렸지만 하루가 지나도록 도출되지 않아서 실패.
그 외에 팀원분이 공유해주신 사이트를 통해 부동산에 영향이 갈만한 요소를 몇 개 눈여겨 보긴 했지만 하나같이 시간을 많이 쏟아야 되는 것이라서 다른 것에 눈길을 돌릴 수 밖에 없었다.

Data Preprocessing
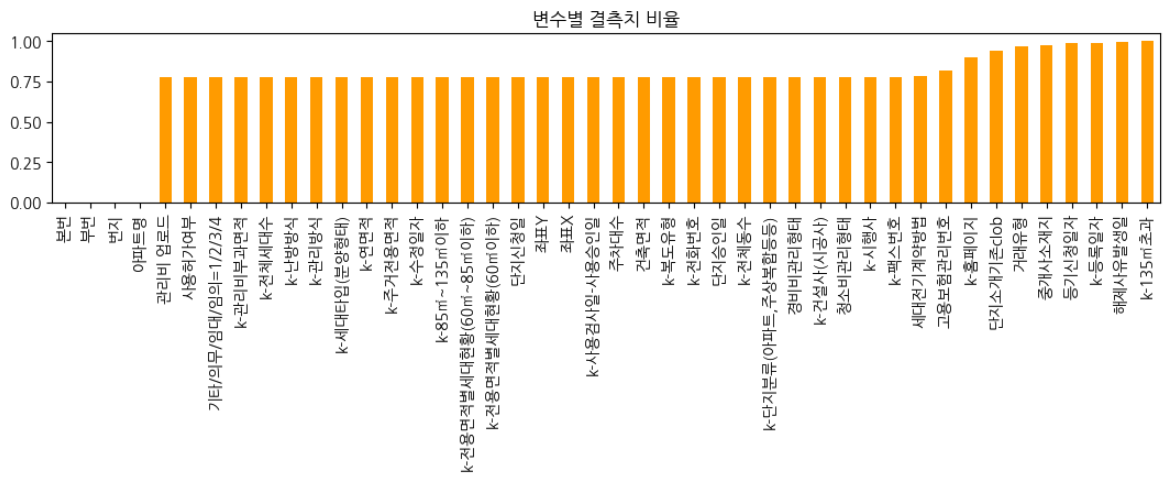
위의 대회 개요에서 알 수 있듯 이 대회의 데이터는 결측치가 어마무시하게 많다.
게시판에 공유된 글이나 다른 팀원들을 보면 결측치가 많은 변수들은 그냥 지워버리고 값들이 온전한 5개 내외의 변수만을 사용하여 모델링을 하곤 했다.
쉬운 방법으로는 하기 싫은 반골 기질 덕분에 결측치를 손수 해결하고자 했고 그 결과 타임오버 되어 유의미한 결과를 도출하기 전에 대회가 끝나버렸다.
아쉬운 마음을 담아 여태 진행한 결측치 해소 방법을 공유해봤는데 9분이나 좋아요 해주셔서 감사할 따름이었다.

Feature Engineering
아무리 부동산에 까막눈이라도 근래 들어 부동산이 엄청나게 뛰어오른 것은 알고 있다.
즉, 대회를 위해서 거품을 반영한 학습 데이터 위주로 학습시켜야 한다는 소리이다. 예측해야하는 데이터의 시점(2023.06~2023.09)조차 거품의 영향을 피할 순 없기에 2020년 이후 데이터만 사용하였더니 cv 결과가 매우 좋아졌다.
그리고 주식을 하는 사람으로서 금리가 상승하면 대출 둔화로 이어지는 점을 고려하여 이는 부동산 매매에도 영향을 미칠 것이라 생각하여 한국은행 기준금리 변수를 추가했다. 그 후 미미한 성능 향상을 볼 수 있었는데 엄청난 결측치를 해소하면 기준금리 변수가 좀 더 성능을 향상 시켜줄 것이라고 생각했다.
주변의 여러 시설물의 여부를 파악하여 해당 여부 변수들을 추가하고 싶긴 했지만 좌표의 결측치들부터 해소하지 하지 못해서 실패!
Modeling
처음 대회의 베이스라인은 RF만 구현되어 있었지만 이전에 만들어뒀던 Regression 베이스라인에서 모델링을 그대로 가져와서 적용시킬 수 있었다.
베이스라인의 묘미를 느낄 수 있었던 순간..! 덕분에 큰 수고를 하지 않아도 성능 향상 효과를 볼 수 있었다.
파라미터 튜닝까지 했으면 더 좋을뻔했지만 Feature Engineering이 우선된 후 진행해야 그 효과를 제대로 보기 때문에 최후의 최후까지 미루다가 결국 두 마리 토끼를 전부 놓치고 말았다. 중간에 타협점을 찾는 것도 좋은 방법이었음을 아득히 떠올리는 순간이었다
Mentoring
ㄱㅇㄷ 강사님과의 멘토링 중 기억에 남는 것은
지역구별로 데이터셋을 나누어 학습시키면? 이었다.
이유는 지역구별 편차가 클 경우에는 데이터셋을 나누어 학습하는게 유의미한 성능 차리가 있을 수도 있다는 것인데
이는 강남/강북 여부로 어느정도 해소되어 다른 Feature Engineering을 우선했다.
5. 자체 평가 의견 : Competition Review
Good point
- 내가 찾은 방안을 커뮤니티에 공유한 것
- 이번 내부 대회를 진행하며 작게나마 차별점으로 생각했던 방안을 공유해봤고 생각보다 많은 좋아요를 받게 되어 떨떠름하면서도 나 하나만이 아니라 더 다양하고 많은 곳에 기여했다는 유익한 느낌을 받을 수 있었다.
- Upstage 대회 이전에 캐글에서도 여러 대회에 참여했지만 인사이트를 공유하는 게시글은 써본 적이 없다. 언제나 도움받는 입장이 되었을뿐…
Fail point
- 좌표 찾는 코드를 실패한 것
- 이를 바탕으로 느낀 것은 새삼 당연하지만 코드가 잘 돌아가는지 소규모로 확인하고 중간중간 잘되는지 확인할 수 있는 방법을 추가하는 것이었다.
- 몇 번째 인덱스까지 됐는지 확인하는 출력문을 추가했다면 모를까 그냥 냅다 돌려버리고 nn시간을 보냈더니 인내심에 한계가 왔다.
- 좌표 찾는 코드 (더보기)
# 필요한 Library 설치
%pip install geopy
from geopy.geocoders import Nominatim
# 관련 Column 만들기
dt01['도로명주소'] = dt01['시군구'] + ' ' + dt01['도로명']
# Geopy Geolocator 초기화
# geo_local = Nominatim(user_agent='South Korea')
geolocator = Nominatim(user_agent="geoapiExercises")
# 지오코딩 함수 정의
def geocode(address):
try:
location = geolocator.geocode(address)
return location.latitude, location.longitude
except:
return None, None
# 결측치가 있는 행의 좌표 대체
for index, row in dt01[dt01['좌표X'].isna() | dt01['좌표Y'].isna()].iterrows():
addr = row['도로명'] # '도로명'을 기반으로 좌표를 얻습니다
lat, lon = geocode(addr)
dt01.at[index, '좌표X'] = lat
dt01.at[index, '좌표Y'] = lon
del dt01['도로명주소']
# 결과 확인
dt01Bummer point
- 예측 후 인사이트를 활용하지 못한 것:
- 그런데 이 대회의 베이스라인은 예측 이후 어떤 Feature가 영향이 컸는지, 예측을 잘 한or잘 하지 못한 top 100 비교, 예측값 시각화 등을 제공하면서이를 이후에도 사용하고 싶었지만 베이스라인에 있는 코드 그대로를 쓰지 못했던게, 당장 앙상블 모델 사용과 시간관리의 미숙함이 발목을 잡았기 때문이었다…
- 피드백의 방향을 제시하는 점이 굉장히 센세이션이었다. MLOPs에 관심있어 하는 내가 이런 기본적인 피드백 수렴을 하지 못했던 것이 조금 부끄럽게 느껴졌다.
- 여태 예측값 도출 후 평가지표에 의존하며 성능이 좋아졌냐 안좋아졌냐만을 반복했다.
- 액기스를 뽑아야하는 시간을 활용 못한 것:
- 사실 대회 시간은 공지가 되어있는데 내가 소화하지 못했을 뿐 조금 더 시간관리의 필요성이 절실하게 된 순간이었다. 휴학 생활하느라 시간의 개념이 많이 확장되어 있었는데 다시금 졸라매리라 다짐했다.
- 개인적인 이유로 대회를 늦게 시작한 것도 있었지만 2주 밖에 안되는 시간이 더욱 원망스럽게 느껴지기도 했다.
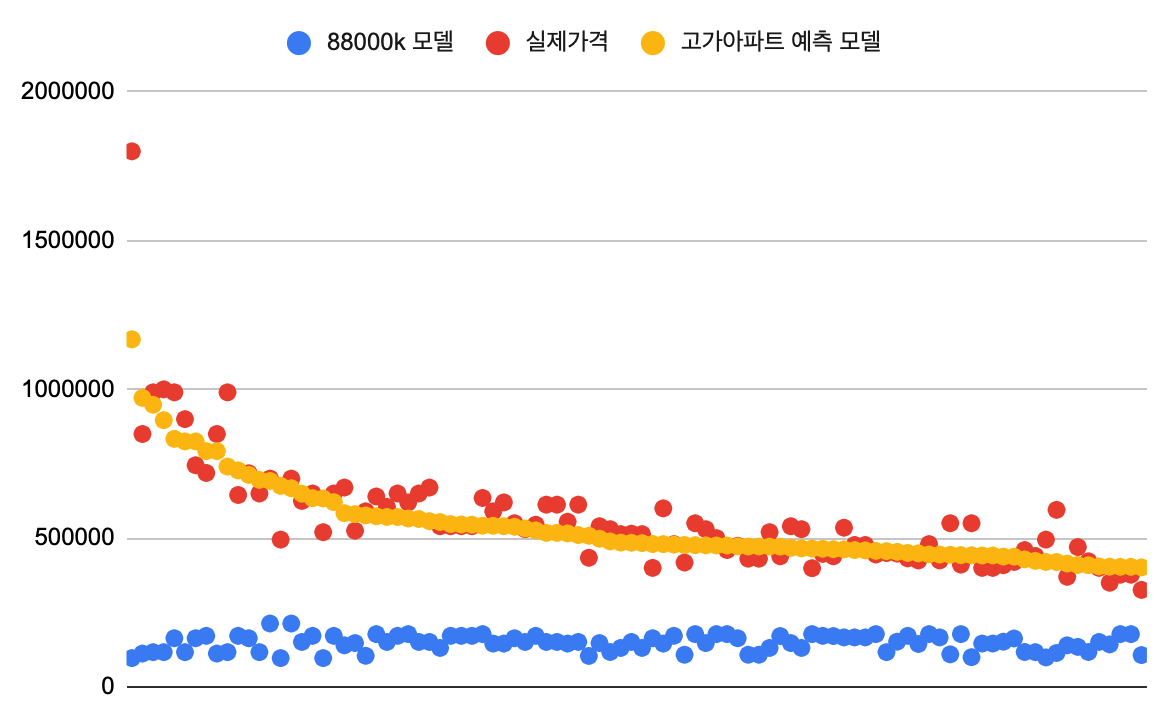
- 대회의 Test dataset에 오류가 있었던 것:
- 처음에 LB의 RMSE가 10만 가까이 나와서 당황했다. 이는 전체 아파트 1개당 10억씩 틀린다는 것을 의미하는데 이는 10억을 호가하는 고가 아파트의 예측이 잘 안되고 있다고 판단하였고 실제로 validation에도 고가 아파트 예측이 잘 안되고 있음을 확인하여 이에 포커스를 맞추면 성능 향상에 크게 도움 될거라 생각했다.
- 하지만 성능 향상의 부진은 여전했고 다른 캠퍼분이 test dataset의 indexing이 잘못된 것이 아닌지 의문을 제기하셨는데 이게 사실이었다... 성능 향상이 잘 이뤄지지 않아서 의욕을 잃어가고 있었는데 오류가 있었다고 하니 허탈한 마음이 들었다.
Insights from the competition
- 중간에 타협하고 앞으로 나아갈 길을 찾자
- 이미 앞에 설명했지만 첨언하자면 파레토 법칙(80 대 20 법칙)이라는게 있다. 80%의 결과는 20% 행위에서 나타난다는 것인데, 다시 말해보자면 열심히 일하는게 아니라 효율적으로 일해야 된다는 것이다. 마침 이 이론을 알게되면서 내가 하고 있는 것이 정녕 우선순위였는가?를 반성할 수 있었고 앞으로를 좀 더 효율적으로 하기 위해 해야 되는 것이 무엇인가를 먼저 생각하게 됐다.
- MLOPs의 과정을 떠올리자
- 기획부터 배포까지, 그리고 피드백 수렴 후 다시 반복.
- 그것이 내가 아는 MLOPs인데도 불구하고 피드백을 그저 숫자에 의존하면서 여태 대회에 임해왔던게 아쉬웠다.
- 이번에는 시간관리의 부족함으로 이를 반영하지 못했지만 이 다음부턴 꼭 적용해볼 것이다.
'개발개발 > 프로젝트' 카테고리의 다른 글
| Upstage AI Lab 대회 회고: [IR] Scientific Knowledge Question Answering (0) | 2024.05.19 |
|---|---|
| Upstage AI Lab 대회 회고: [NLP] Dialogue Summarization (0) | 2024.05.12 |
| Upstage AI Lab 대회 회고: [CV] Document Type Classification (1) | 2024.03.23 |
| 패스트캠퍼스 매출 데이터 분석 : EDA 프로젝트 회고 (2) | 2023.11.23 |