


0. 발표자료: Link
#3 CV Competition | 문서 타입 분류 | 7조
Computer Vision 문서 타입 분류 대회 www.fastcampus.co.kr Copyright ⓒ FAST CAMPUS Corp. All Rights Reserved. 무단전재 및 재배포 금지 7조 김윤겸, 남영진, 노균호, 이재민, 윤수인 #UpstageAILab1기 #ComputerVision
docs.google.com
1. 대회 개요 : Competition Overview
■ Goal of the Competition
- 문서 타입 데이터셋을 이용해 17개의 클래스로 이미지 분류 모델 구축
■ Timeline
- February 5th, 2024 - Start Date
- February 19th, 2024 - Final submission deadline
■ Dataset
- train [폴더] : 1570장의 이미지 저장
- train.csv
- 1570개의 행,
train/폴더에 존재하는 1570개의 이미지에 대한 정답 클래스 제공 ID학습 샘플의 파일명target학습 샘플의 정답 클래스 번호
- 1570개의 행,
- meta.csv [파일]
- 17개의 행
target17개의 클래스 번호class_name클래스 번호에 대응하는 클래스 이름
- test [폴더] : 3140장의 이미지가 저장
- sample_submission.csv [파일]
- 3140개의 행
ID평가 샘플의 파일명target예측 결과가 입력될 컬럼 (값 전부 0으로 저장)
2. 대회 목표 : Competition Detailed Goal
■ Learning Objective
- 공동 학습 목표
- 1차 목표(Basic): Backbone 이해하기
- 1차 목표 선정이유
- 김**: 정형데이터에서도 overfitting으로 애먹었기에 cv의 overfitting 핸들링이 궁금
- 남** : CV의 기본이 되는 Backbone들을 정확히 이해하는 것이 다른 task를 이해하는 데에 기본이 될 것이라고 생각해 깊게 공부해보고 싶습니다.
- 윤** : 실전에서 Overfitting을 방지하기 위한 방법을 알고, 미리 대비하여 스코어를 잘 받아보고 싶다.
- 1차 목표 선정이유
- 2차 목표(Advanced): Semantic Segmentation 이해하기
- 2차 목표 선정이유
- 남** : Semantic Segmentation과 관련해 프로젝트를 진행해 본 적이 있는데, 개념적인 내용과 함께 더 깊은 이해를 하고 싶습니다.
- 노**: 의료 영상이나 이미지에서 부위나 객체를 식별하는 방법을 배워보고 싶습니다.
- 윤** : 실제 대회가 어떤 방식인지 아직은 모르지만, 문서에서 Background 영역이 크다고 생각해서 발생하는 문제와 해결방법을 배우고 싶다.
- 2차 목표 선정이유
- 1차 목표(Basic): Backbone 이해하기
- 개인 학습 목표
- 1차 목표: CV Competition 나만의 Baseline 만들기
- 2차: CV에서 overfitting 줄이는 방법 조사 및 적용
3. 모델 구조 요약 : Competition Model
(flowchart로 대체 예정)
■ Data
- Fix mislabeled Train Dataset : 6 row
- Augmentation
- Oversampling
- Albumentation
- Mixup
■ Modeling
- Model: maxvit_small_tf_512
- batch 사이즈: 8
- epoch=60
- optimizer : AdamW
- weight decay=1e-4
- CrossValidation : kfold=5, early stopping
- Ensemble :
- Do: Ensemble of 5 fold, Ensemble of 7 final predictions
- How to: mode
- Ensemble of 7 final predictions
- Random seeds: 5
- Another optimizers(Adam, NAdam): 2
■ Result
- F1 score :
- Public LB : 0.9529
- Private LB : 0.9409
- Ranking 4/9
4. 진행 과정 : Competition Process
■ EDA
- Train-Test 분포 확인
우선 Train과 Test 폴더 별 이미지 분포를 살펴봤다. Train 이미지는 노이즈 없이 깨끗한데 반해 Test 이미지는 이미 여러 Augmentation 기법이 적용되어 있었다.
- Train dataset target 오류 수정
공유 게시판에서 장*준님의 게시글을 보고 알았는데 target이 잘못된 데이터가 있다는 것이었다. 그리하여 엑셀 파일에 아이디별로 이미지가 삽입되게끔 코드를 구성하여 새로운 엑셀 파일 생성하였다. 그러고 시작된 1570장 훑어보기… 그래도 그 결과 6개의 잘못된 데이터를 찾을 수 있었고 매우 미미하긴 하지만 오류를 고칠 수 있었다. 오류는 의료 문서 쪽이 대부분이었는데 진료 확인서가 소견서로 되어있다든가 영수증이 진단서로 되어있다든가 하는 헷갈릴 수 있는 경우들이었다. (근데 단순하게 전후 성능 비교해 보니 오히려 떨어졌다 뭐지?)
- Train dataset 클래스 불균형 확인

데이터가 불균형하면 성능이 안 좋기 마련이다. epoch 수를 늘리면 이 차이는 점점 벌어져 점차 적은 클래스에 대해 무시하는 방향으로 학습이 될 것이기 때문이다. (점차 가중치가 줄어들 것이므로)
■ Augmentation
- Oversampling:
- Train dataset에만 적용하여 모델 검증 정확성 보장
- 특정 클래스에 더 높은 가중치 부여를 통해 Dataset의 클래스 불균형 해소
- 각 클래스별로 설정된 비율에 따라 데이터를 샘플링

- Albumentation
- 이미지 랜덤 회전: 90°/180°/270°/360° 중 랜덤 회전
- 이미지 뒤집기: 수평 또는 수직 방향의 랜덤 뒤집기
- 가우시안 노이즈 추가: 정규분포 노이즈의 적용
- 블러 효과 적용: 모션, Median, 일반 블러 중 선택 적용
- 외곽 회전 보완: 회전 후 남는 외곽을 흰색으로 채움
- 이미지 왜곡 처리: 광학, 그리드, 어파인 변환 중 선택 적용
- 이미지 향상 처리:CLAHE, 샤프닝, 엠보싱 중 선택 적용
- 밝기 및 대비 조정
- 색조, 채도 조정
- 이미지 크기 조정 및 정규화: 크기 조정, mean 및 std를 이용한 정규화

■ Modeling
- 모델 변천 과정:
Resnet50 - maxvit_xlarge_tf_512 - maxvit_xlarge_tf_334 - maxvit_small_tf_512
- 최종 모델 선택 이유
처음엔 Resnet50으로 빠르게 학습을 돌리며 데이터나 각종 configure를 조정했다. 하지만 F1 스코어 기준 80대에서 벗어나지 못하여 모델 쪽으로 눈을 돌려보고자 하였는데 마침 팀원이 SOTA 모델인 Maxvit을 알려줬다.
Maxvit은 Maximizing Vision Transformer의 약자로, ViT 기반 최신 CV 모델 중 하나이며 기존 ViT에 비해 크게 두 가지 개선점을 갖고 있었다.
- 하이브리드 아키텍처:
- 트랜스포머 블록과 CNN 레이어를 결합하여 더욱 강력한 특징 추출
- 이미지의 로컬 특징과 글로벌 특징을 모두 포착 가능케 함
- 스케일링 전략: 다양한 크기의 이미지에 대해 효율적으로 작동
- 위 장점과 함께 때마침 멘토님께서 시간이 한정되어 있으므로 모델을 픽스하고 데이터나 파라미터에 좀 더 집중하는 게 시간대비 성능을 끌어올리기 좋을 수 있다고 하셔서 그대로 Maxvit으로 픽스하기로 했다.
- Maxvit 표류기
Maxvit을 쓰기로 했지만 팀원이 최초로 소개해준 모델인 maxvit_xlarge_tf_512은 epoch 30에만 꼬박 약 5시간이 걸렸다. 일단 xlarge 자체가 maxvit에서 제일 파라미터가 많은 데다가 이 모델을 사용하면 대회용 GPU(RTX3060 24GB)로 구동 가능한 batch size가 1밖에 안 됐기에 overfitting과 다른 configure를 조정할 시간을 확보하려면 더 작은 크기의 모델이 필수였다.
그리하여 Maxvit 논문을 살펴보며 크기별, 해상도별 Maxvit 모델 비교 분석을 했고, 일반 이미지보다 더 높은 해상도가 요구되는 문서의 특성을 고려하여 해상도 512 사이즈를 고집하면서도 batch size가 조금이라도 늘어날 수 있는 모델을 선택했다.
그 결과로 선택된 것이 maxvit_small_tf_512이며, 더 큰 모델에 비해 성능도 체감할 정도로 차이가 나지도 않고 학습 시간은 무려 약 1시간 반 정도로 줄었다.
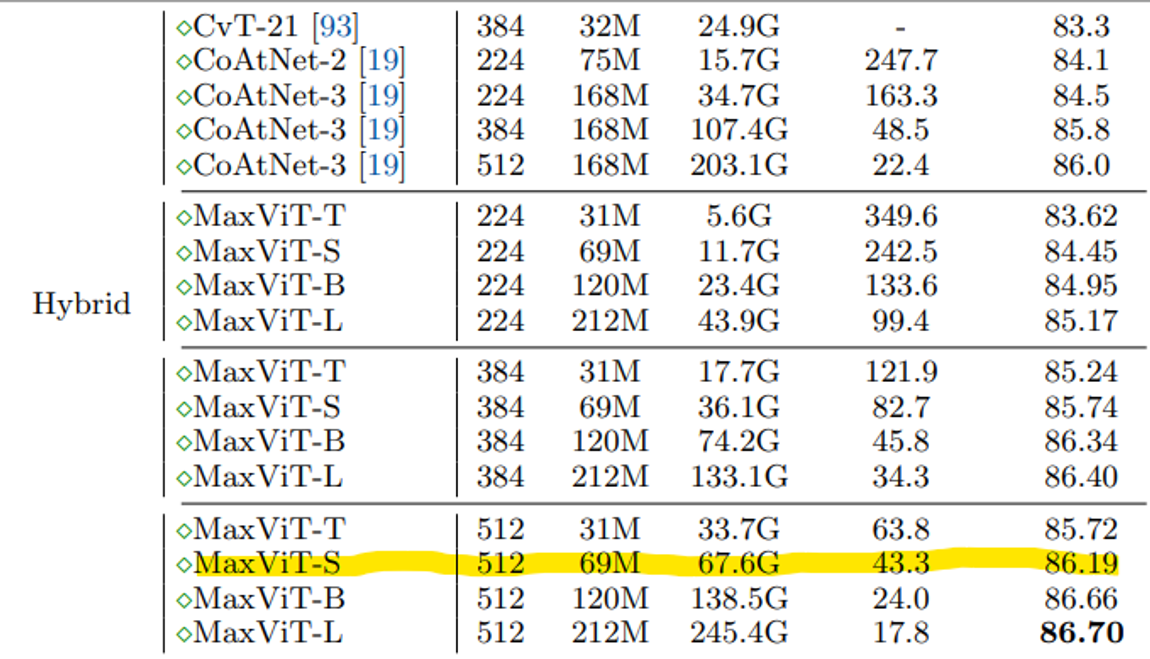
그리고 이건 후에 멘토링 때 알게 된 것인데 Early stopping을 적용할 땐 batch size가 커야 안정적으로 loss 수렴이 이루어져 early stopping이 제대로 작동한다는 것이다. 역시 어떻게든 batch를 늘리려는 노력은 헛되지 않았던 것 같다. 아래 사진을 참고하자.
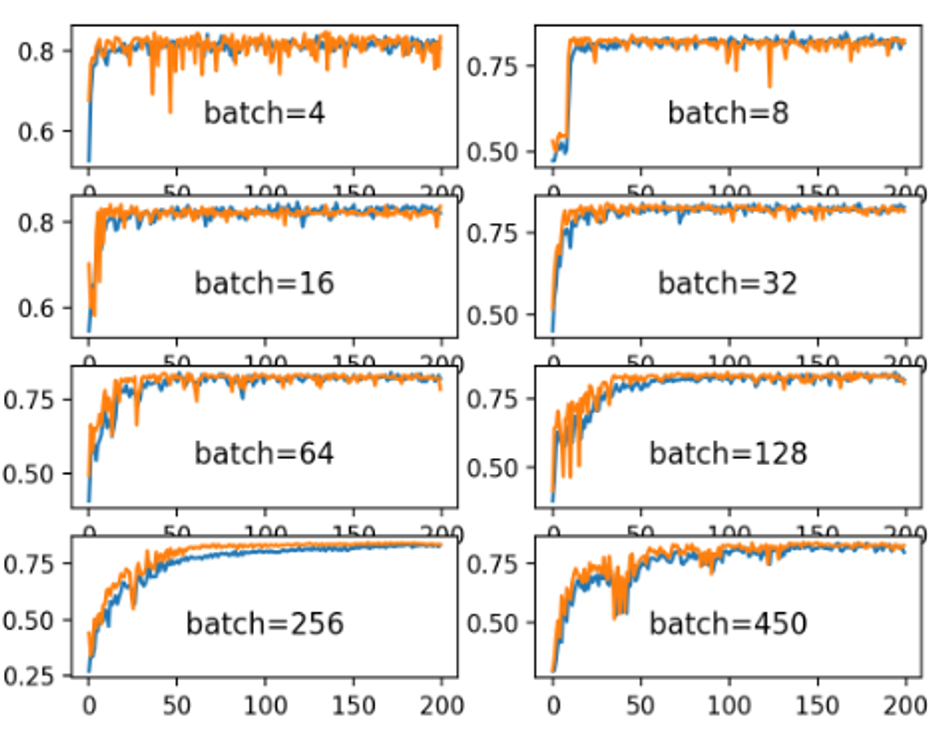
- optimizer 선택 및 튜닝
처음에 팀원이 maxvit과 함께 들고 온 optimizer는 NAdam이었다. 바로 쓰기보단 다른 것을 먼저 신경 쓰고 있었기에 Adam을 고집하다가 성능 한계에 부딪히고 나서야 NAdam을 들여다보게 됐다. 그러나 maxvit 논문에서는 AdamW만을 쓰고 있었기에 3개의 optimizer의 특징을 파악하고 직접 비교분석하기도 했지만 멘토님께서 마침 optimizer와 관련하여 weight decay 파라미터를 조정해 보는 것을 추천하셨기에 이와 관련 있는 AdamW에 좀 더 집중해 보기로 하였다. 아래는 당시 정리했던 각 optimizer 별 특징이다.
✅ Adam과 NAdam과 AdamW의 차이
※ Adam은 각 매개변수마다 학습률을 적응적으로 조정하는 최적화 알고리즘
- 적응적 학습률: 매개변수별로 다른 학습률 적용
- 모멘텀 & 스케일링 조합: 과거 - 그래디언트의 정보를 활용
- 바이어스 보정: 초기 학습 단계의 바이어스 보정을 통해 안정적인 학습
※ NAdam은 Adam에 네스테로프 가속을 추가한 알고리즘
- 네스테로프 가속 추가: 미래의 그래디언트 변화를 예측하여 수렴 속도 개선
- Adam의 기능 유지: 적응적 학습률, 바이어스 보정 등 Adam의 주요 기능 포함
※ AdamW는 Adam 알고리즘에서 Weight Decay를 다루는 방식을 개선
- Weight Decay를 손실 함수에 추가하는 대신, 매개변수 업데이트 단계에서 직접 가중치를 감소시키는 방식- - AdamW는 일반화 성능을 개선하고, 원하는 Weight Decay 효과를 보다 명확하게 달성 가능
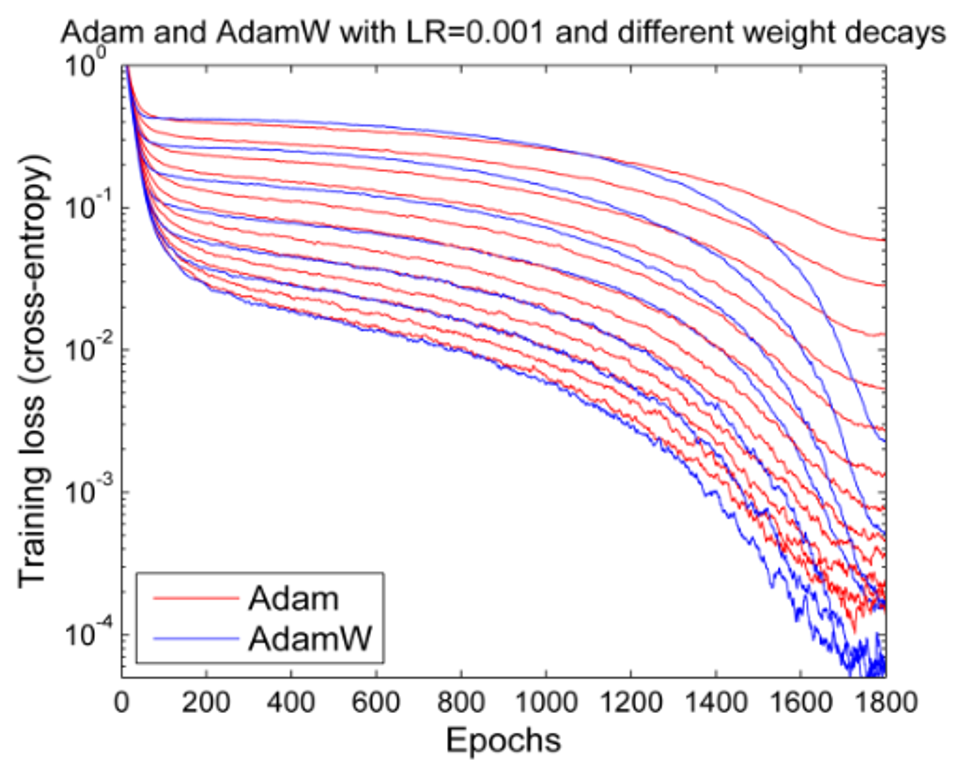
- Cross Validation with KFold
정형데이터에선 막힘없이 쓰던 kfold가 이미지 데이터에선 막혀버렸다. dataloader를 쓰기 때문일까? GPT와 다소 씨름을 통해 기존의 train-test split을 k-fold로 바꿀 수 있었다. 사실 멘토님께선 얼마 남지 않은 대회 기간 동안 시간대비 효율이 좋지 않다고 하셨는데 overfitting에 노이로제 걸린 나는 그냥 구현했다.
그런데 이게 웬걸? fold별로 1시간 반씩 걸리길래 early stopping 구현도 필수였다. ML에서는 모델 자체에 구현되어 있거나 콜백 함수로 쉽게 쓸 수 있었는데 CV에서는 라이브러리를 사용하자니 뭔가 틱틱 걸리는 느낌이고, 리턴이나 출력이 원하는 데로 되지 않아서 직접 구현했다.
- Early Stopping 코드
class EarlyStopping:
def __init__(self, patience=5, verbose=False, delta=0):
self.patience = patience
self.verbose = verbose
self.delta = delta
self.early_stop = False
self.val_loss_min = np.Inf
self.counter = 0
# 최적의 에폭, 모델, train loss, val loss, es에폭
self.best_epoch = 0
self.best_model = None
self.best_score = None
self.best_train_loss = None
self.stopped_epoch = 0 # Early Stopping이 발생한 에폭
def __call__(self, epoch, val_loss, train_loss, model):
score = -val_loss
if self.best_score is None:
self.best_score = score
self.update_best_model(epoch, train_loss, model)
elif score < self.best_score + self.delta:
self.counter += 1
if self.verbose:
print(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience:
self.early_stop = True
self.stopped_epoch = epoch
else:
self.best_score = score
self.update_best_model(epoch, train_loss, model)
self.counter = 0
def update_best_model(self, epoch, train_loss, model):
self.best_epoch = epoch
self.best_train_loss = train_loss
self.best_model = copy.deepcopy(model.state_dict())
if self.verbose:
print(f'New best model at epoch {epoch+1} | Train Loss: {train_loss:.4f}')
def print_summary(self):
print(f"Early stopping at epoch {self.stopped_epoch+1}. Best at epoch {self.best_epoch+1}")- Ensemble은 간단하게
대회 기간이 길지 않았기 때문에 정형 데이터처럼 여러 모델을 voting 앙상블까지 하기엔 시간이 부족하여 단일 모델을 사용하거나 간단한 앙상블을 사용해야 했다.
우선 당장 fold별 예측 결과들을 앙상블 해야 했기에 자주 사용하는 평균으로 했다가 예측값이 망가져 당황했었다. 이유를 생각해 보니 연속적이거나 확률을 맞추는 것이 아닌 특정 클래스로 예측해야 하는데 예측값들을 평균해버리면 전혀 상관없는 이상한 값이 나와버리는 것이다. 그러다가 생각한 것이 최빈값으로, 매우 간단한 데 비해 결과도 준수하게 나와서 이 방법을 선택하게 됐다. 물론 대다수의 예측값이 잘못 나오면 낭패긴 하겠지만 LB 제출 결과 실제로 준수하게 나왔다.
평균으로 망가지는 예시) 특정 아이디에 대해 어떤 예측은 1(진단서)로, 또 다른 예측은 16(소견서)으로 예측했을 때 평균 해버리면 9(자동차 번호판)가 돼버리는 것
최빈값 앙상블은 최종 예측값들에도 쉽게 적용할 수 있어서 총 7개의 예측값들을 앙상블 했다. 원래는 seed만 서로 다른 예측값들만 사용할랬는데 optimizer를 교체하는 과정에서 if 문에 실수를 하여 adam과 NAdam이 조금 섞여 들어갔다. 실수를 알고 AdamW로 교체했을 때는 대회 종료까지 얼마 남지 않아서 고민이 되기도 했지만 다양성을 좀 더 높이고자 전부 다 기용해서 앙상블 후 마지막 제출 했더니 다행스럽게도 개인 제출 중 가장 높은 점수로 마무리할 수 있었다.
■ Mentoring
- 📝 #1 질문 사항
- Q1. kfold는 사용이 가능한지? 효용성 있는지?
- Q2. albumentation과 augraphy 중복은 잘 안 쓰는 경우인지?
- 문서 유형 따라 다르게 적용?
- 이미지 유형은 albumentation, 문서 유형은 augraphy
- (차 번호판, 차 대시보드 / 진단서, 소견서 등)
- 문서 유형 따라 다르게 적용?
- Q3. 어떤 모델 사용?
- Q4. 멘토님이 쓰시는 앙상블?
- ✅ #1 피드백 내용
- A1. 하면 좋을 수 있겠지만 시간과 메모리 관점에서 비추천
- A2. 잘 안 씀
- 좋은 생각인 듯, ImageDataset 오브젝트에 타깃 유형에 따라 달라지도록 정의
- A3. 모델도 좋지만 optimizer의 다양한 하이퍼 파라미터 사용 및 튜닝 추천
- maxvit은 논문을 보면 AdamW를 씀(논문에 표로 어떻게 썼는지 정리되어있음)
- ImageNet-1K (fine tuning) 따라가는 것 추천
- 라벨 스무딩 적용
- A4. 잘 안씀, 하나를 잘 튜닝하는 것을 추천하는 편
- 📝 #2 질문 사항
- Q1. 표를 참고했을 때, 스케쥴러는 사용하지 않는 게 좋은 것 같아서 사용해보진 않았는데 참고가 될까요?
- Q2. 모델이 큰 게 좋을지, 사진 사이즈(해상도)가 큰게 좋을지?(+albumentation, augraphy 같이 쓰니까 메모리 초과)
- Q3. 예측값 제출 시 description(configure) 어떻게 작성하는지?
- Q4. 최종 예측값 앙상블의 경우 최빈값 외에 좋은 방법이 있을지?

- ✅ #2 피드백 내용
- A1. 일반적인 이미지가 아닌 문서 분류 이므로 lr를 크게 해서 pre-training 추천
- lr 스케쥴러는 이때 효과적임
- pre-trained 가중치를 쓰더라도 스케쥴러는 효과 있을 듯
- A2. 사진 사이즈 384와 512의 성능 차이는 크지 않음(근소하게 512가 크긴 함)
- 사이즈는 표준 224를 많이 쓰고 욕심내면 384를 씀, 과욕하면 512를 쓰는 정도
- 배치 사이즈가 작으면 loss 수렴이 매우 튈 수 있기에 배치 사이즈 키우는 것을 추천
- 최소 8이고, 보통 64 이상 추천
- loss가 튈 경우, early stopping이 잘 안 될 수 있음
- A3. wandb로 configure 체크 중, 협업할 때도 좋음
- A4. 최종 예측값을 도출하기 전이라면 몰라도 개별 예측값끼리는 최빈값으로 하는 게 맞음
- A1. 일반적인 이미지가 아닌 문서 분류 이므로 lr를 크게 해서 pre-training 추천
5. 자체 평가 의견 : Competition Review
■ Good point
- overfitting을 잡기 위해 노력한 것:
비록 팀 내 최고점은 아니었지만 public과 private 점수의 갭 차이가 크지 않았다. 0.01 정도? 최고점을 받았던 다른 팀원의 제출물은 0.02 이상 차이 나서 private LB에서는 나와 점수 차이가 거의 나지 않았다.
- batch size를 늘린 것:
다른 팀원의 경우 batch size 1로 고정하여 사용하느라 다양한 시도를 못했었는데 반해 꽤 다양한 시도를 해본 것 같다. 이번에 팀 발표 시간에 CAFomer라는 가볍고 강력한 모델이 있던데 batch size도 32로 진행했다고 하니 한번 시도해 볼만할 것 같다.
■ Fail point
- maxvit으로 batch size를 더 늘리지 못한 것:
지금 생각해 보면 tiny 모델을 시도해 봐도 좋았을 텐데 하는 마음이 있다. CV에서도 F1 스코어가 0.9702 정도에 그쳤기에 좀 더 안정적으로 early stopping 이뤄졌다면 더욱더 높일 수 있었지 않았을까 싶다.
- augraphy를 사용 실패:
문서에 특화된 데이터 증강 기법인데 코드에 이를 적용하면 메모리 이슈로 다운 됐었다. 다른 팀원들보다 모델이 무겁지 않은데도 이런 현상이 발생하니 기가 막힐 노릇이었다. 데이터 중에는 자동차 대시보드, 번호판 같은 비문서(?) 데이터도 있기는 했지만 대다수가 종이로 된 문서 데이터였기에 문서/비문서 타깃별로 augraphy와 albumentation을 각각 적용하려는 날카로운 방법도 고안했지만 메모리 이슈로 실패하니 아쉬웠다.
■ Bummer point
- 클래스 별 오차 확인 못한 것:
예측 후 클래스 별로 얼마나 오차가 있는지 확인했으면 좀 더 성능 개선을 효율적으로 할 수 있었을 것 같은데 이것을 대회 막바지에 알아서 아쉬운 마음이 있다. 학습 코드에 한번 적용시켜 봐야겠다.
- 좀 더 다양한 모델 시도를 못한 것:
발표 때 보니 efficientnet-b4라는 모델이 자주 보였다. 나의 경우 resnet50에서 maxvit으로 퀀텀점프한 거나 다름없기에 좀 더 천천히 스텝을 밟아갔다면 다양한 경우를 확인할 수 있지 않았을까 하는 생각이 든다.
■ Insights from the competition
- CV의 직관적인 매력이 있다:
tabular에 feature engineering이 있다면 CV에는 Augmentation이 있다. tabular의 경우 도메인이 많은 영향을 끼치는 데 반해 CV에선 눈에 보이는 만큼 처리하면 되니 좀 더 직관적인 매력이 있는 것 같다.
- Early stopping을 적용할 땐 batch size를 적어도 32를 유지하자
위에도 계속 언급했듯 batch size는 너무 적어도, 너무 많아도 문제다. 적당한 size를 유지할 수 있도록 하자!
'개발개발 > 프로젝트' 카테고리의 다른 글
| Upstage AI Lab 대회 회고: [IR] Scientific Knowledge Question Answering (0) | 2024.05.19 |
|---|---|
| Upstage AI Lab 대회 회고: [NLP] Dialogue Summarization (0) | 2024.05.12 |
| Upstage AI LAB 대회 회고 : [ML] House Price Prediction (1) | 2024.03.17 |
| 패스트캠퍼스 매출 데이터 분석 : EDA 프로젝트 회고 (2) | 2023.11.23 |