


0. 발표자료: Link
#4 NLP Competition | 일상 대화 요약 | 6조
Dialogue Summarization 일상 대화 요약 www.fastcampus.co.kr Copyright ⓒ FAST CAMPUS Corp. All Rights Reserved. 무단전재 및 재배포 금지 6조 김윤겸, 남영진, 노균호, 윤수인, 정다슬 #UpstageAILab1기 #NLP
docs.google.com
1. 대회 개요 : Competition Overview
■ Goal of the Competition
- 다양한 주제의 대화문을 바탕으로 요약문을 생성하는 모델 구축
■ Timeline
- March 8th, 2024 - Start Date
- March 20th, 2024 - Final submission deadline
■ Dataset
- train.csv : 12457*4
- dev.csv : 499*4 (validation dataset)
- test.csv : 500*2 (Public: 250, Private: 250)
- 데이터 구성
- 최소 2 턴, 최대 60 턴으로 대화가 구성, 대화(dialogue)를 보고 이에 대한 요약(summary)을 예측하는 것이 최종 목표
- fname : 대화 고유번호 (중복 X)
- dialogue : 최소 2명에서 최대 7명이 등장하여 나누는 대화 내용. 각각의 발화자를 구분하기 위해#Person”N”#: 을 사용하며, 발화자의 대화가 끝나면 \n 으로 구분.
- summary : 해당 대화를 바탕으로 작성된 요약문

■ Evaluation_metric
- 3개의 요약문과 예측한 요약문을 비교하여 *ROUGE metric 바탕으로 score 계산
- 하나의 대화에서 다양한 관점으로 작성된 3개의 요약문 평가
- 모델의 다양성을 고려하여 더 일반적으로 측정하기 위함
- 정확한 ROUGE score 산출하기 위하여 문장 토큰화를 진행한 후 평가
- ROUGE
- 텍스트 요약, 기계 번역과 같은 Task를 평가하기 위해 사용되는 대표적인 metric
- 모델이 생성한 요약본(+번역, …)과 사람이 만든 참조 요약본을 비교하여 점수 계산
- ROUGE-Recall: 참조 요약본을 구성하는 단어들 중 모델 요약본의 단어들과 얼마나 많이 겹치는지 계산한 점수
- ROUGE-Precision: 모델 요약본을 구성하는 단어들 중 참조 요약본의 단어들과 얼마나 많이 겹치는지 계산한 점수
- ROUGE-N과 ROUGE-L
- ROUGE-N : unigram, bigram, trigram 등 문장 간 중복되는 n-gram 비교하는 지표
- ROUGE-L : LCS 기법을 이용해 최장 길이로 매칭되는 문자열을 측정. n-gram에서 n을 고정하지 않고, 단어의 등장 순서가 동일한 빈도수를 모두 세기 때문에 보다 유연한 성능 비교가 가능

2. 대회 목표 : Competition Detailed Goal
■ Learning Objective
- 공동 학습 목표 ⇒ NLP 전반에 대한 이해도 상승, 대회를 통한 실습 진행
- 개인 학습 목표 ⇒ NLP competitinon 첫 베이스라인 만들기
- 이해 기반의 베이스라인 생성을 통해 NLP에 대한 관심을 다시 한번 환기하고 싶었다. NLP와 관련하여 이전에 진행한 맥주 리뷰 감정 분석 프로젝트에서는 감정 분석 이후 합류하여 토픽 모델링 구현에만 힘을 쏟았을 뿐 정작 이론에는 큰 비중을 두지 않았었기 때문에 이번 기회를 통해 NLP의 이곳저곳을 건드려보고자 하는 마음으로 임하였다.
3. 모델 구조 요약 : Competition Model
■ Data
- Fixing Train Dataset Error: 1 row
- Add Special Tokens
- Utilize ‘topic’ columns of the Train, Dev dataset
- Topic Modeling (Use kobart-summarization)
- Post-processing
- Remove space between 주어 and 조사
- Remove Indentation
■ Modeling
- Model: kobart-summarization
- batch 사이즈: 50→32
- Hyper-Parameter Tuning
- Grid Search, Random Search
■ Result
- ROUGE - Final Score :
- Public LB : 42.5202 / Ranking 3rd
- Private LB :39.7159 / Ranking 4th (up)
4. 진행 과정 : Competition Process
■ EDA
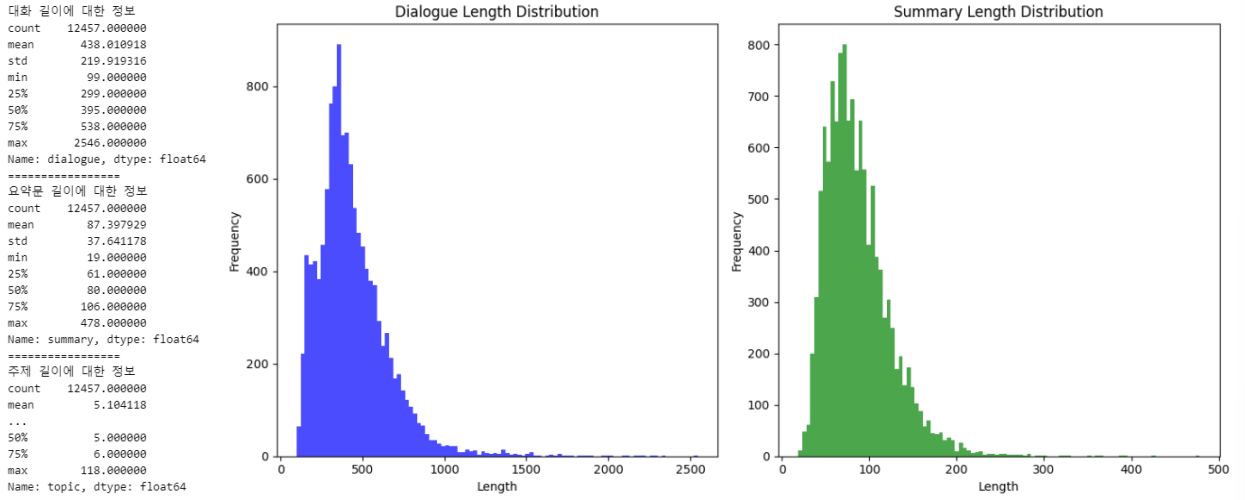
- Max_length 설정
우선 요약문이 안정적으로 생성되도록 최대 길이를 정하고자 주어진 데이터들(dialog, summary)의 길이를 파악했다.
최초 설정된 인코더, 디코더 최대 길이나, 생성 최대 길이는 보수적으로 설정되었음을 아래 이미지를 통해 알 수 있었다.
다만 이래저래 실험을 한 결과 최초 설정값이 제일 성능이 높게 나와서 별다른 조치는 취하지 않았었다. (근데 다른 팀은 아예 팍팍 높게 설정해서 성능 향상을 이뤘었다.)
- Special Tokens 확인
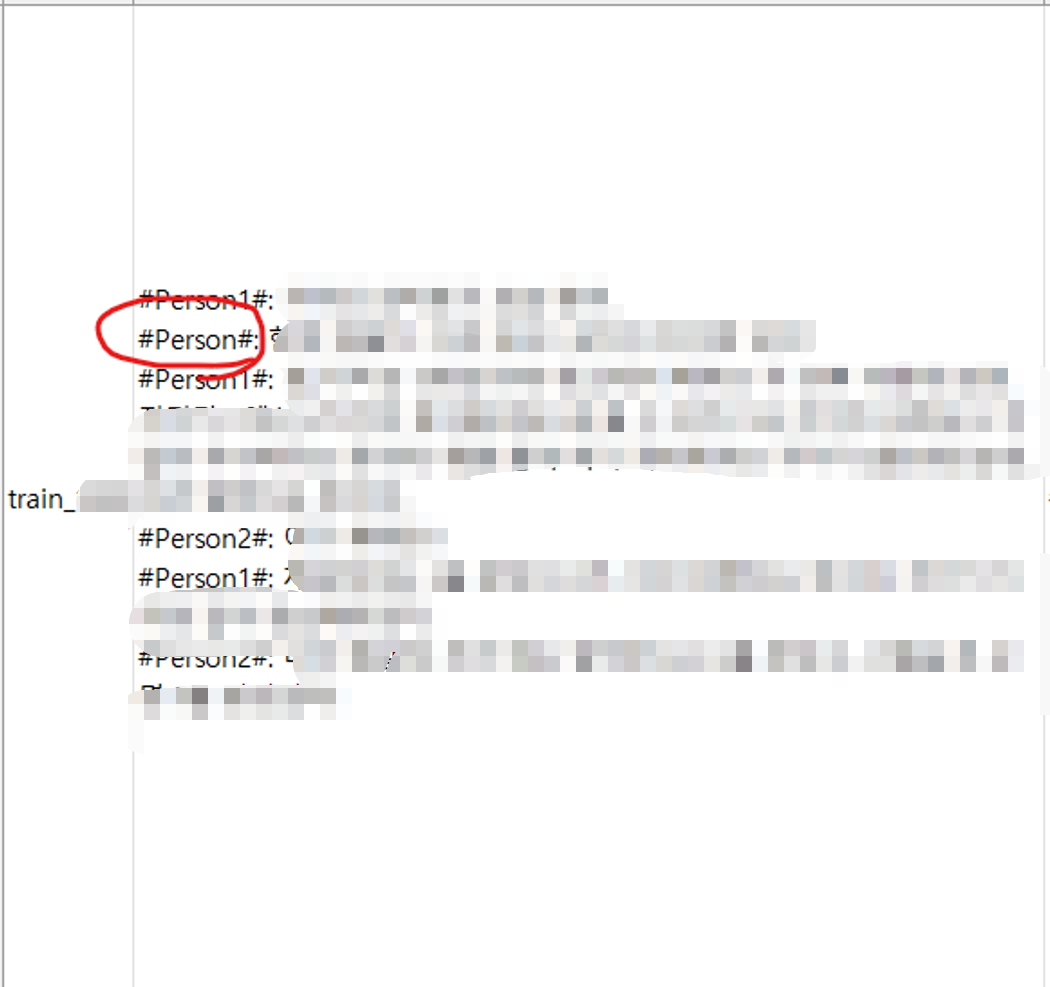
운영진 측이 추가로 공개한 대회 설명에 따르면 개인 정보는 마스킹되어 있다는 것이었다. 그리고 발화자 또한 구분되어 있기에 이런 것들이 학습되지 않도록 Special Token 처리해주는 게 필요했다. 다행히 어렵지 않게 ‘#\w+#’ 정규식 패턴으로 추출할 수 있었고 유니크값을 뽑아 아래 리스트를 도출할 수 있었다.
['#Person1#', '#Person2#', '#Person3#', '#Person4#', '#Person5#', '#Person6#', '#Person7#', '#Address#', '#CarNumber#', '#CardNumber#', '#DateOfBirth#', '#Email#', '#PassportNumber#', '#PhoneNumber#', '#SSN#', '#주제#’]
위 리스트에는 사실 #Person#이라는 토큰이 하나 더 있었는데, 혼잣말이어도 숫자가 붙는 발화자 토큰의 특징 상 이건 오류라고 판단되었다. train 데이터셋을 직접 살펴봤을 때 다행히 하나의 행에서만 이 문제를 발견할 수 있었고 금방 고칠 수 있었다.
■ Data
- Topic 메타데이터 활용
다양한 피쳐를 이용하는 ML대회와 달리 NLP는 모두가 당연하다는 듯 대화문만을 가지고 모델링을 수행했다. 그러나 Train과 Dev 데이터셋에는 어째서인지 topic 컬럼도 있었고 test 데이터셋에는 있지 않았다. 이때 딱 어떻게든 써먹어야 봐야겠다는 생각이 스쳐 지나갔고, 곧이어 이런 생각이 들었다. “LLM의 Clarity with Delimiters 특징을 이용하면 되지 않을까?”
비록 베이스라인은 하나의 Task만을 다루는 언어모델이지만 LLM의 전신인만큼 충분히 가능성 있어 보였고, 실제로 성능 향상을 이뤄냈다. 근데 topic 예측은 기가 막히게 잘해서 조금 웃픈 면이 있었다. 과정은 아래와 같다.
- 베이스라인 모델(kobart-summarization) 활용 (Extractive 방식이 아닌 Abtractive 방식 필요했기 때문)
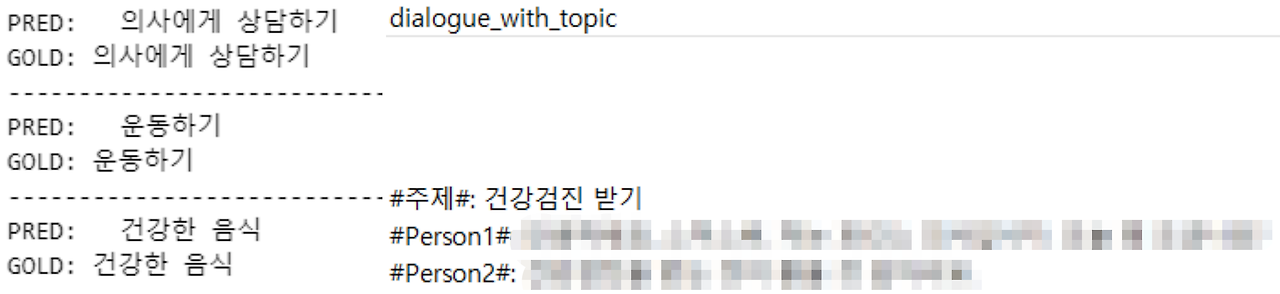
- Train-set과 validation-set의 topic 컬럼을 타겟으로 학습 후 test-set에 topic 예측
- 메타 데이터 학습을 위해 topic과 dialogue를 합친 dialogue_with_topic 컬럼 추가 후 해당 컬럼으로 요약문 학습 및 예측
- topic 처리를 위한 Special token 추가


- 전처리 같은 후처리
성능을 올리기 위해 정체가 되었을 무렵 조금 이르게 후처리를 시작하게 됐다. 예측 결과를 분석한 결과 주어-조사 간의 띄어쓰기 문제가 있고 큰따옴표와 들여 쓰기가 무분별하게 분포되어 있는 것을 확인했고 이것을 처리했을 때 성능 0.01 정도 상승되었다.
- #PersonN# 과 조사 (은,는, 이, 가, 에게,를 등등) 사이 띄어쓰기 제거
- 따옴표가 생기는 경우 -> 실제로 ""가 들어가 있는 것이 아닌, csv파일 처리하는 과정에서 생긴 문자
- 들여 쓰기 제거
■ Modeling
- Model: kobart-summarization
이번엔 Data-centric에 집중하기 위해 모델에 대해선 보수적으로 접근했다. 모델 찾는 것은 다른 팀원에게 역할을 배분했었는데 결국 돌고 돌아 베이스라인의 모델을 사용하기로 했다. 유력한 후보 중에 BART와는 다른 방식인 KoT5도 있었지만 Batch size 문제로 도입에는 실패했다.
비록 최신 언어 모델은 사용하지 못했지만, 결과적으로 일찍이 Data-centric 했던 것은 좋은 접근이었던 것 같다. 후에 현직자분께서 이제는 모델링을 고민하기보다 어떻게 잘 학습시킬 것인지가 관건이라는 말씀이 더욱더 이 접근에 힘을 실어주었기 때문이기도 하다.
- Hyper-Parameter Tuning
이 부분은 다른 팀원이 맡았는데 아쉽게도 극적인 성능 향상은 이뤄내지 못했었다. 일찍이 범용적인 파라미터값으로 성능 향상을 확인하고 추후 따로 조치한 것은 없었다.
■ Result
- ROUGE - Final Score :
Public LB : 42.5202 / Ranking 3rd
Private LB :39.7159 / Ranking 4th (shakeup)
내 제출파일은 팀 내 Public score 기준 2등은 아니었다. 다만 방향성을 달리 하고자 제출 파일 2개 중 하나로 내 파일이 제출했는데 shakeup이 일어나면서 Private LB에서는 내 제출파일이 팀을 캐리 하게 됐다. 하마터면 등수가 2등 떨어질 뻔했는데 나름 뿌듯하다.

■ Mentoring
개인적인 이유로 멘토링 시간에 참여하지 못했지만 결론적인 내용은 아래와 같았다.
- 목적 : 내 모델의 tokenizer가 요약문에 있는 token을 알고 있어야 한다. (tokenizer 성능 높이기)
- 방법 0 : EDA에서 진행했던 내용 기반으로 토큰 추가
- 방법 1 : 정답 문장을 few-shot으로 train set에 넣어서 학습시킨다.
- 방법 2 (Data Distillation) : GPT-4 (LLM)을 통해 다양한 요약문을 생성하고, 이 요약문들을 train set으로 넣어준다.
5. 자체 평가 의견 : Competition Review
■ Good point
- 일찍이 Data-Centric에 집중한 것:
위에도 흠뻑 언급했지만 여태 대회 경험을 통해 대세는 Model-centric 보다 Data-centric임을 깨달을 수 있었다. 역할 배분에서 양해를 구하고 이를 도와준 팀원분들에게 감사할 따름이다.
■ Fail point
- 한국어 최신 언어 모델 사용 실패:
팀원이 KoT5의 Batch size 오류를 해결하기 위해 Upstage 멘토님께도 물어보며 사방팔방 뛰어다녔지만 아쉽게도 해결하지 못한 채 베이스라인 그대로 가게 되었다. 베이스라인 자체로도 훌륭한 모델이긴 했으나 약 3년 전 모델이기 때문에 최신 언어 모델을 사용했으면 어땠을까 하는 생각이 있다.
■ Bummer point
- 좀 더 다양한 기법을 적용해보지 못한 것
대회 종료 후, 발표 및 피드백 시간에 토크나이저가 생각보다 엄청나게 중요하다는 것을 알게 됐다. 대회 1등의 방법론을 나열하자면 Data Cleaning, SOLAR-KO-10.7b(토크나이저)+QLoRA, 4bit Quantization, bf16, batch=8, SFT, 1 epoch였다. LLM을 적극적으로 활용했고 무거운 모델 사용이 가능했던 것은 좋은 토크나이저를 썼기 때문이라는 설명을 들으며 토크나이저에 대해 더 알고 싶은 마음이 들었다.
그리고 augmentation을 적용한 팀도 여럿 있었는데 AI 허브에서 일상 대화 데이터셋을 추가하는 방법과 Back-translation 등을 통해 기존 데이터셋을 증강하는 방법이 있었다. 번역으로 augmentation 하는 것도 놀라웠는데 LLM을 통해 한국어 to 한국어 번역이 바로 가능하다는 점도 놀라웠다. LLM은 [Source Language = Target Language = Korean] 이렇게 설정함으로써 쉽게 가능하다는 사실…!
■ Insights from the competition
- 토크나이저의 중요성
좋은 토크나이저일수록 의미 있게 잘 자르고 낭비되는 토큰이 없기에, 맥락을 더 잘 이해하고 사용 메모리가 줄어 학습이 안되던 거대 모델도 학습이 가능해진다는 것이었다. NLP에 있어서 굉장히 중요한 것을 배운 기분…! 현재 부트캠프 외에 다른 NLP 프로젝트를 진행 중이었는데 당장이라도 적용해보고 싶은 마음이 드는 순간이었다.
'개발개발 > 프로젝트' 카테고리의 다른 글
| Upstage AI Lab 대회 회고: [IR] Scientific Knowledge Question Answering (0) | 2024.05.19 |
|---|---|
| Upstage AI Lab 대회 회고: [CV] Document Type Classification (1) | 2024.03.23 |
| Upstage AI LAB 대회 회고 : [ML] House Price Prediction (1) | 2024.03.17 |
| 패스트캠퍼스 매출 데이터 분석 : EDA 프로젝트 회고 (2) | 2023.11.23 |